通义系列的Qwen2.5 – Omni全模态大模型,包括其能处理多种输入并合成输出文本与语音的功能,在权威测试中的表现,采用的创新技术架构,小尺寸带来的产业应用优势,以及免费商用的情况。


在人工智能技术不断发展的当下,Qwen2.5 – Omni横空出世,它是通义系列模型中首个端到端全模态大模型。这一独特的大模型具备卓越的能力,能够同时处理多种不同类型的输入,其中涵盖了文本、图像、音频和视频等。更为厉害的是,它可以实时合成输出文本与自然语音。这一强大功能,无疑为用户与模型之间的交互带来了全新的体验。
想象一下,用户如今能够和Qwen进行语音聊天以及视频通话,仿佛在与一个真实的人交流。对于这样的新奇体验,网友们表现出了强烈的欣喜之情,大家纷纷期待着它能在更多领域发挥作用。
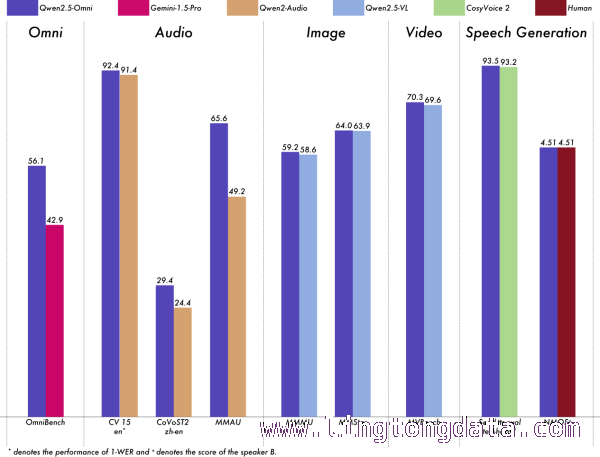
事实上,Qwen2.5 – Omni的实力并非仅仅停留在表面。在一系列同等规模的单模态模型权威基准测试中,它在语音生成测评分数上达到了与人类持平的能力。这一数据结果为该模型在语音和视频通话方面的可行性提供了坚实的数据支撑,进一步证明了它在技术上的先进性和可靠性。
Qwen2.5 – Omni之所以拥有如此强大的功能,离不开其背后先进的技术。在具体技术方面,它采用了通义团队全新首创的Thinker – Talker双核架构、Position Embedding融合音视频技术、位置编码算法TMRoPE(Time – aligned Multimodal RoPE)。
其中,双核架构Thinker – Talker为Qwen2.5 – Omni赋予了类似人类的“大脑”和“发声器”。Thinker承担着处理和理解用户输入内容的重要任务,就像人类的大脑一样,对各种信息进行分析和解读。而Talker则负责输出相应的语音标记,如同人类的发声器,将思考的结果以语音的形式表达出来。通过两者的紧密配合,完成了端到端的统一模型架构,实现了实时语义理解与语音生成的协同,让模型的交互更加自然和流畅。
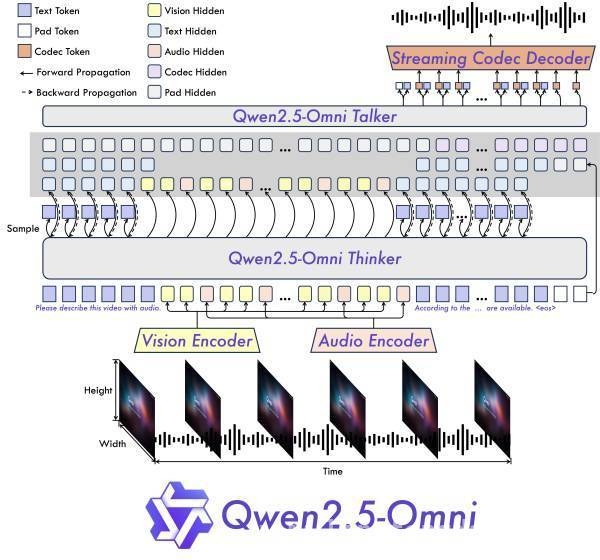
TMRoPE算法也发挥着关键作用。它通过时间轴对齐实现了视频与音频输入的精准同步,使得模型能够准确地捕捉到不同模态数据在时间维度上的对应关系。这就好比为模型装上了一双“慧眼”,让它能够看清各种数据之间的时间关联,从而为生成连贯、准确的内容提供了有力保障。
值得一提的是,Qwen2.5 – Omni以7B的小尺寸展现出了巨大的优势,它让全模态大模型在产业上的广泛应用成为了可能。以往,由于模型尺寸过大,很多应用场景受到了限制。而现在,用户即使在手机上,也能轻松部署和应用Qwen2.5 – Omni模型,大大拓展了其应用范围。
目前,开发者和企业迎来了一个好消息,他们可以免费下载商用Qwen2.5 – Omni。这一举措无疑将加速全模态大模型在各个产业的推广和应用,为人工智能技术的发展注入新的活力。
本文详细介绍了Qwen2.5 – Omni全模态大模型的功能、测试表现、技术架构、尺寸优势以及商用政策。该模型具备处理多种输入并合成输出的能力,技术创新先进,小尺寸便于产业应用,且免费商用,有望推动全模态大模型在各产业的广泛应用。
原创文章,作者:Nelson,如若转载,请注明出处:https://www.lingtongdata.com/6134.html