本文介绍了约翰霍普金斯与ETH Zurich联合推出的自主科研智能体框架AgentRxiv,阐述了其能让智能体相互协作、共享研究成果以提高科研效率的特点,并通过多项测试展示了其在提升智能体性能等方面的效果,最后对智能体研究成果的创新性进行了探讨。


在当今科技飞速发展的时代,AI的应用范围不断拓展。令人惊喜的是,AI不仅具备写论文的能力,还能够自主开展科研协作,这无疑为科研领域带来了全新的变革。约翰霍普金斯与ETH Zurich联合推出的自主科研智能体框架AgentRxiv,便是这一变革中的关键成果。该框架打破了智能体之间“孤岛”式的存在,允许智能体相互上传和检索研究成果,自动积累并迭代已有进展,从而显著提高了研究效率。
我们不妨大胆设想一下,当有一天AI智能体能够帮我们自主进行研究、查阅文献时,每个人的科研产出或许将实现质的飞跃。然而,现实情况是,目前的AI智能体大多处于各自为战的状态,无法实现协作以及传承既有的研究成果。为了解决这一问题,霍普金斯联手ETH Zurich的研究人员精心打造了AgentRxiv这一专为自主研究智能体设计的框架。它的出现,就像是为智能体之间搭建了一座沟通的桥梁,让它们能够上传、检索并相互借鉴研究成果。

论文地址:https://agentrxiv.github.io/resources/agentrxiv.pdf
简单来讲,AgentRxiv就如同一个“预印本服务器”。它不仅可以让研究者为智能体设定研究方向,使其持续产出论文,更重要的是,它能确保每一篇新作都是建立在以往研究基础之上的,实现真正意义上的迭代式进步。

经过一系列测试,在数学推理任务中,基于AgentRxiv的智能体在开发全新推理技术时,会主动参考前人的研究报告。以gpt – 4o mini为例,其准确率从70.2%提升至78.2%,相较基线和思维链分别飙升了11.4%、9.7%。此外,在AI智能体发现最佳算法(SDA)的多项基准测试中,SDA平均提升了3.3%的准确性。更值得关注的是,在三个独立实验室通过AgentRxiv共享预印本并行实验中,最优方法的准确率高达79.8%,相较基线提升了13.7%。这充分表明,与传统的序列实验相比,这种协作模式能够更快速地达成关键里程碑,从侧面印证了AgentRxiv在加速研究进程方面具有巨大的潜力。

现有的研究框架往往独立运行,生成的研究成果就像一个个孤立的“孤岛”,智能体之间完全处于“隔离”状态。这种隔离严重限制了科学发现的累积进展和泛化。在科学研究中,我们都知道研究成果通常是建立在前人工作的基础之上的,也就是所谓的站在“巨人的肩膀”上。为了让智能体也能从协作共享中受益,就需要一种结构化的机制来打破这些“孤岛”,而AgentRxiv正是这样的机制。
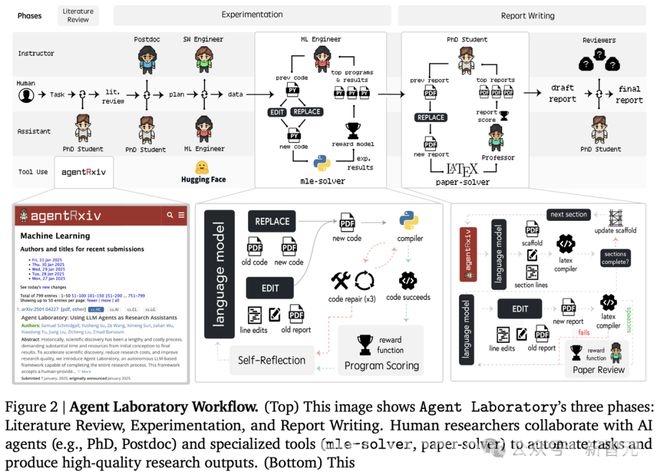
智能体实验室的工作流程主要包括三个阶段:文献回顾、实验和报告撰写。在这个过程中,人类研究员会与AI智能体(例如博士、博士后)以及专门工具(mle – solver、paper – solver)展开合作,将任务自动化,从而产出高质量的研究成果。

从图中可以看到两个独立的自主智能体实验室通过AgentRxiv进行互动的过程。左侧的实验室提交搜索请求,从AgentRxiv检索出相关研究论文;右侧实验室完成实验后将研究成果上传至AgentRxiv,供其他实验室查阅。
为了验证智能体是否能基于自身过往研究不断优化成果,研究人员进行了一系列实验。首先使用o3 – mini(medium)作为LLM后端能力,运行智能体系统产出了N = 40篇论文。在文献综述阶段,智能体可以同时访问AgentRxiv上的5篇论文和arXiv上的5篇论文。然后设定了一个研究方向:“通过推理与提示工程提升在MATH – 500上的准确率”,实验中使用的是OpenAI的gpt – 4o mini模型。
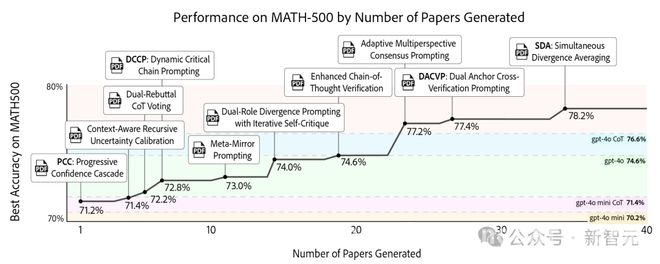
从实验结果可以看出,每篇新论文的产生都带来了准确率的稳步提升。一开始,gpt – 4o mini的基准表现为70.2%。通过一些早期策略,准确率有了小幅提升,达到了71.4%。随着推理策略的不断引入,最终SDA策略将准确率提升到了最高的78.2%。
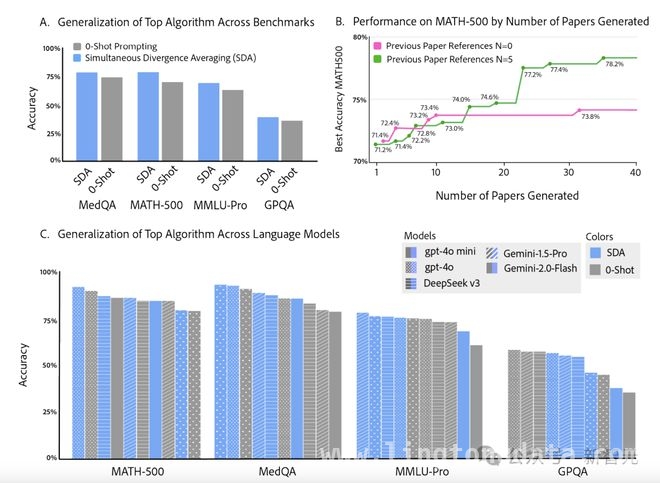
进一步评估SDA策略是否能在其他数据集上展现类似效果。在GPQA(生物/化学/物理研究问答)、MMLU – Pro(跨学科推理)和MedQA(美国医学执照考试)这三个基准上,SDA均带来了显著提升:GPQA从36.4%提升到38.9%(提升了6.8%);MMLU – Pro从63.1%提升到70.8%(提升了12.2%);MedQA从74.9%提升到81.6%(提升了8.9%)。三项基准平均提升9.3%,与MATH – 500上的11.4%表现接近,说明SDA拥有较强的泛化能力。研究人员还测试了SDA在不同语言模型上的表现,包括Gemini – 1.5 Pro、Gemini – 2.0 Flash、DeepSeek – v3、gpt – 4o、gpt – 4o mini。结果显示,SDA在所有模型上都带来了平均3.3%的性能提升,尤其是在基础表现较差的模型上效果更明显(如gpt – 4o mini提升5.9%)。
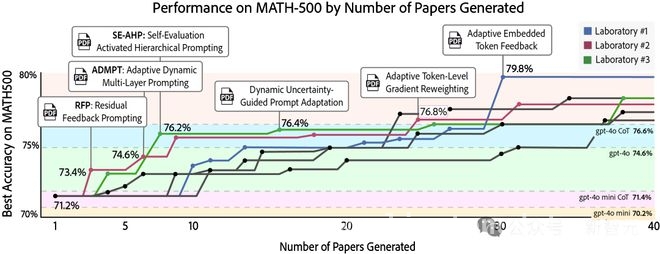
接下来,研究人员探索了多个自主实验室并行运行、并借助AgentRxiv实现研究成果共享的效果。他们初始化了三个配置相同、研究目标一致的Agent Laboratory系统,并行运行。每个实验室独立完成文献综述、实验设计与论文撰写,同时通过AgentRxiv异步访问其他实验室发布的论文。一旦某个实验室上传了新的研究成果,其他实验室即可即时获取,并在后续实验中加以利用。当某个实验室在性能上有所突破时,相关论文就会上传到AgentRxiv,供其他实验室查阅、评估和借鉴。这种并行设置允许多个研究方向同时推进,有望加快发现的速度。在并行设置下,早期里程碑如达到76.2%的准确率仅需7篇论文,而在顺序设置下则需要23篇论文。并行设计中表现最好的算法比最佳的顺序算法提高了1.6%,并且并行实验的整体平均准确率比顺序运行高出2.4%。
尽管已有研究表明LLM能提出创新性的研究想法,但也有研究指出这些系统存在高比例的“抄袭”问题(最高达24%)。然而,AI完全生成的研究成果已经开始被正式学术会议接收。虽然会议收录不能完全证明内容新颖,但至少说明这些成果足以“看起来像新发现”。研究人员对上述表现最好的论文摘要进行了3个不同查重系统的检测,结果均未发现抄袭痕迹。他们还对这些论文进行人工检查,发现高表现算法确实包含一定创新,但很多是对已有技术的“变种”或“组合”,而非完全原创。比如上述智能体实验室在开发SDA时,确实参考了许多相关研究。这也表明:虽然SDA在实现与整合上具备一定新意,但是否构成“实质性原创”,在快速发展的领域中难以一锤定音。因此未来仍需进行大规模的系统性研究。
下面为大家介绍一下该研究的作者情况。
Samuel Schmidgall是约翰霍普金斯大学电子与计算机工程系的二年级博士生,同时也是Google Deepmind医疗AI团队的研究员。他在2024年夏天是斯坦福大学医疗AI的实习生,在2024年秋天是AMD Gen AI团队的实习生。

Michael Moor是一名医学博士和哲学博士,研究领域是医疗保健领域的机器学习。自2024年末起,他被任命为位于巴塞尔的苏黎世联邦理工学院(D – BSSE)的医学人工智能方向的终身教职助理教授。在此之前,Michael Moor在斯坦福大学计算机科学系与Jure Leskovec教授一起做了博士后研究,研究重点是开发和评估大规模医疗基础模型,最终目标是解锁适用于医疗AI的通用模型。
参考资料:
https://x.com/SRSchmidgall/status/1904172864355410065
https://agentrxiv.github.io/
https://arxiv.org/pdf/2503.18102
本文详细介绍了约翰霍普金斯与ETH Zurich联合推出的自主科研智能体框架AgentRxiv,它打破了智能体之间的“孤岛”状态,实现了智能体间研究成果的共享与协作,显著提高了科研效率。通过多项测试验证了其在提升智能体性能和算法泛化能力等方面的效果,同时探讨了智能体研究成果的创新性。虽然目前在创新性界定上存在一定争议,但AgentRxiv无疑为科研领域带来了新的发展机遇,未来值得进一步深入研究。
原创文章,作者:Nelson,如若转载,请注明出处:https://www.lingtongdata.com/4852.html