本文聚焦OPPO研究院和港科广科研人员提出的新技术OThink – MR1,介绍了该技术如何基于动态强化学习帮助多模态语言模型突破泛化推理能力,并通过一系列实验验证了其效果。
你是否想过,用上动态强化学习,多模态大模型也能实现泛化推理了?这个看似大胆的设想,如今正逐步成为现实。
来自OPPO研究院和港科广的科研人员们带来了一项令人瞩目的新技术——OThink – MR1。这项技术将强化学习扩展到多模态语言模型领域,旨在帮助模型更好地应对各种复杂任务和全新场景。
研究人员明确表示,这一技术有望使业界在多模态泛化推理能力方面实现重大突破。


我们都知道,多模态大模型具备处理多种类型输入数据并生成相关输出的能力。然而,当面对复杂推理任务时,其表现往往不尽如人意。
目前,在多模态模型的训练中,大多数采用的是监督微调(SFT)的方法。
监督微调就如同老师给学生划定重点,让学生按照固定的模式去学习。这种方法在特定任务上能够让模型有不错的表现,但却难以培养模型关键的通用推理能力。
与此同时,强化学习(RL)作为另一种训练方法,开始受到人们的关注。
强化学习就像是让学生在不断尝试的过程中学习,做得好就给予奖励,做得不好则会受到“批评”。从理论上来说,这种方法可以让模型更灵活地应对各种任务,提升其推理能力。但它也存在一些问题,比如多模态任务通用能力未得到充分探索,训练约束容易导致次优瓶颈等。
在这样的背景下,OThink – MR1技术应运而生。
那么,它究竟是如何让多模态模型突破泛化推理能力的呢?
基于动态强化学习
OThink – MR1是一个基于动态强化学习的框架和模型,它支持对多模态语言模型进行微调。
其核心有两大“招式”:一个是动态KL散度策略(GRPO – D),另一个是精心设计的奖励模型。这二者相互配合,使得模型的学习效率和推理能力得到了大幅提升。
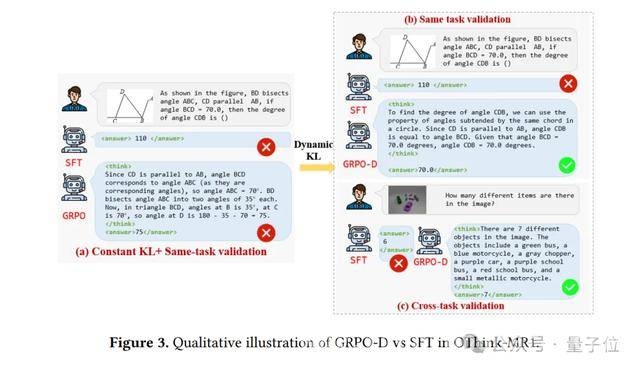
动态KL散度策略
在强化学习中,探索新的策略和利用已有经验是两个至关重要的方面。然而,以往的方法很难平衡这二者的关系,要么在探索阶段浪费过多时间,要么过早地依赖已有经验。
而动态KL散度策略就像是给模型安装了一个“智能导航仪”,能够根据训练进度动态调整探索和利用的平衡。
打个比方,在训练初期,它会让模型像一个充满好奇心的孩子,大胆地去探索各种可能的策略。随着训练的推进,它又会引导模型逐渐利用之前积累的经验,沿着更可靠的路线前进。
这样一来,模型就能更有效地进行学习,避免陷入局部最优解。
奖励模型
在OThink – MR1中,奖励模型就如同老师给学生打分的标准。
对于多模态任务,科研人员设计了两种奖励:一种是验证准确性奖励,另一种是格式奖励。
例如在视觉计数任务中,如果模型准确数出了图片里物体的数量,就能获得验证准确性奖励;同时,如果模型的回答格式符合要求,比如按照规定的格式写下答案,还能得到格式奖励。
这两种奖励相结合,就像老师从多个方面给学生打分,让模型清楚自己哪些地方做得好,哪些地方还需要改进,从而更有针对性地进行学习。
实验环节
为了验证OThink – MR1的实力,科研人员开展了一系列实验。
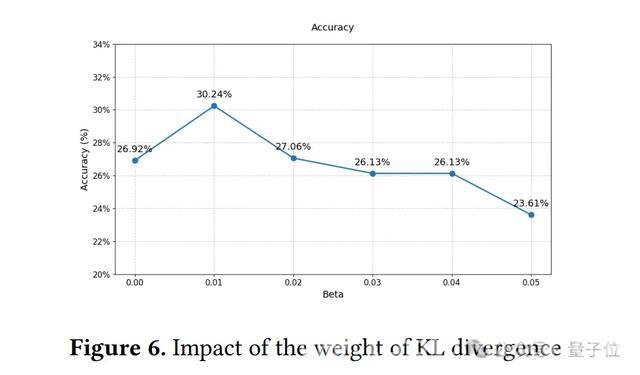
第一个实验是探究奖励项和KL散度项对原始GRPO(一种基于强化学习的方法)在同任务验证中的影响。
在几何推理任务中,科研人员调整格式奖励的权重,结果发现当格式奖励的权重不为零时,模型的表现明显更好。这就如同学生写作文,不仅内容要正确,格式规范也能加分,有助于学生更全面地提升自己的能力。
同时,在调整KL散度的权重时,他们发现权重适中时模型表现最佳,太大或太小都会导致模型成绩下降。
第二个实验是跨任务评估,这可谓是一场真正的“大考”。
以往的研究大多只在同一个任务的不同数据分布上评估模型的泛化能力,而这次实验直接让模型挑战完全不同类型的任务。
科研人员选择了视觉计数任务和几何推理任务,这两个任务难度不同,对模型的能力要求也有所差异。
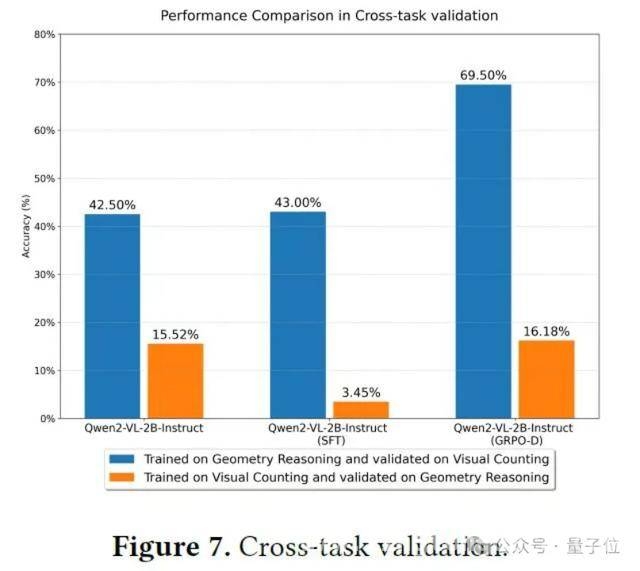
在跨任务验证中,用监督微调训练的模型表现十分糟糕。就像一个只会做一种题型的学生,换了另一种题型就完全束手无策。
而经过GRPO – D训练的模型则表现出色。在从推理任务到理解任务的泛化实验中,它的成绩相比未经过训练的模型有了显著提高;在从理解任务到推理任务的泛化实验中,尽管难度更大,但它也取得了不错的进步。
这就好比一个学生不仅擅长数学,还能快速掌握语文知识,展现出了很强的学习能力。

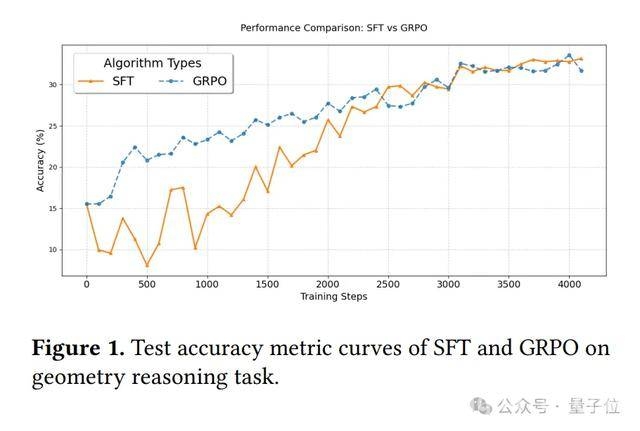
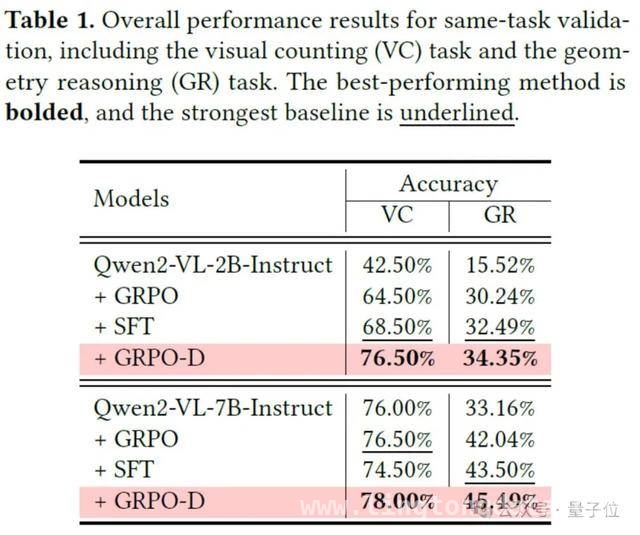
第三个实验是同任务评估。
实验结果显示,在同任务验证中,采用固定KL散度的GRPO方法不如监督微调,但OThink – MR1中的GRPO – D却实现了逆袭。
它在视觉计数和几何推理任务上的成绩都超过了监督微调,这就像一个原本成绩一般的学生,找到了适合自己的学习方法后,成绩突飞猛进,直接超过了那些只会死记硬背的同学。
总体而言,OThink – MR1的出现,为多模态语言模型的发展开辟了新的道路,有望推动该领域取得更显著的进步。
本文围绕OPPO研究院和港科广提出的OThink – MR1技术展开,先阐述了多模态大模型在复杂推理任务中面临的困境以及现有训练方法的不足,接着介绍了OThink – MR1基于动态强化学习的核心策略和奖励模型,最后通过一系列实验验证了该技术在提升多模态模型泛化推理能力方面的有效性,表明其为多模态语言模型发展带来了新的方向。
原创文章,作者:melissa,如若转载,请注明出处:https://www.lingtongdata.com/7967.html